Documentation Index
Fetch the complete documentation index at: https://docs.benchgen.com/llms.txt
Use this file to discover all available pages before exploring further.
Agent Learning Loop
BenchGen is built around one idea: agents should improve themselves. Every run through the platform produces better agents, richer trajectory data, and tighter evaluations — automatically.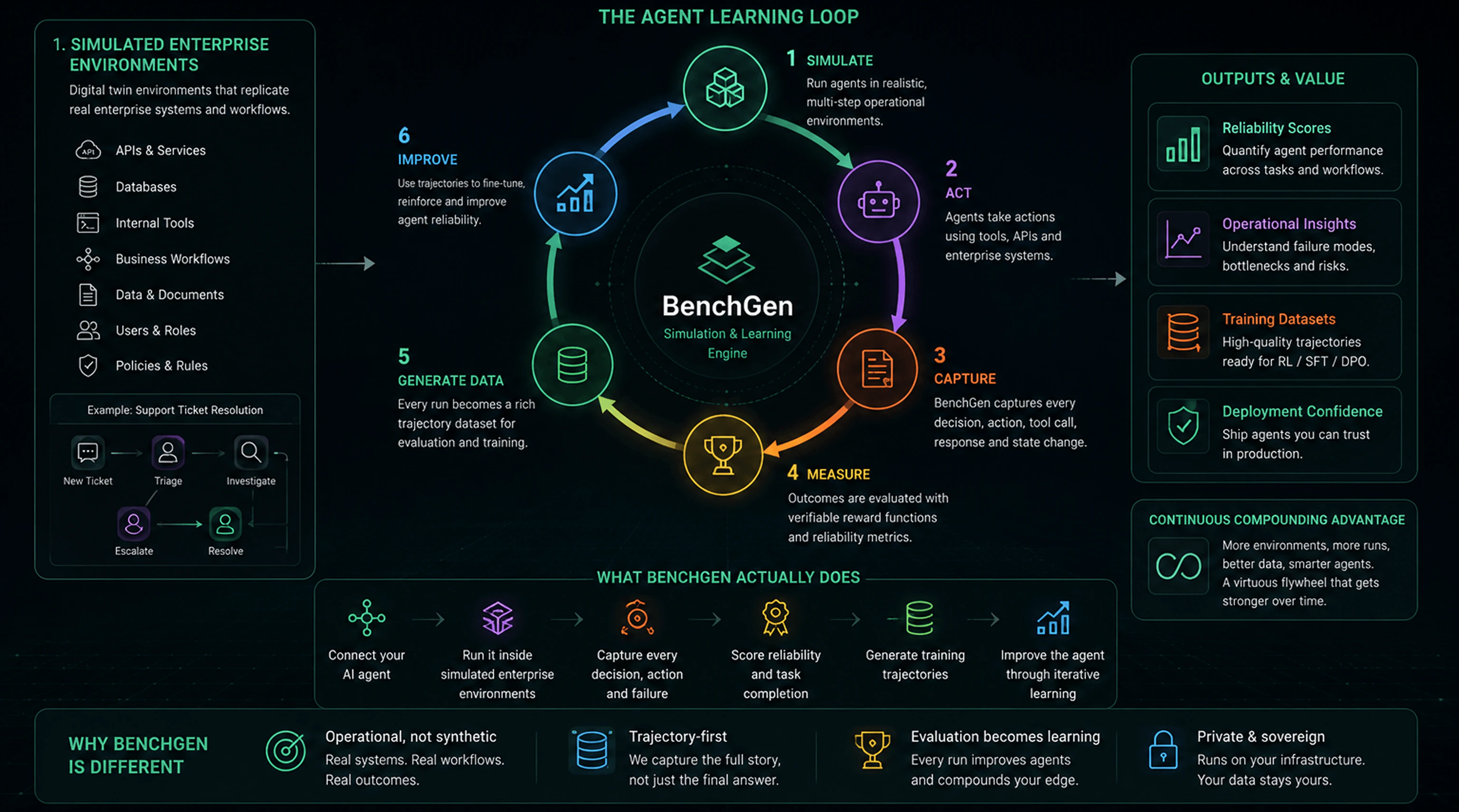
The Six Stages
1. Simulate
BenchGen connects your agent to a digital twin of your enterprise environment — replicating your APIs, databases, internal tools, business workflows, documents, and access policies. Agents operate in realistic, multi-step scenarios that mirror production without the risk. Output: a controlled environment where every agent run is observable and repeatable.2. Act
The agent takes actions inside the simulation using real tools, APIs, and enterprise systems — the same integrations it will use in production. No toy tasks, no simplified APIs. Output: real interaction traces across the full action space.3. Capture
BenchGen records every decision, tool call, API response, and state change during the run. Nothing is summarized or discarded — the full trajectory is preserved. Output: high-fidelity trajectories ready for evaluation and training.4. Measure
Outcomes are evaluated automatically using verifiable reward functions and reliability metrics. BenchGen scores task completion, reliability, and failure modes — without needing human review. Output: structured results that surface exactly where and why the agent failed.5. Generate Data
Every run becomes a labeled training dataset. Successful trajectories become positive examples; failures become signal for improvement. BenchGen generates the data that would otherwise require expensive human annotation. Output: a rich trajectory dataset ready for RL, SFT, or DPO training.6. Improve
Trajectories feed directly into training. BenchGen fine-tunes the agent with LoRA using the captured data, reinforcing good behaviors and correcting failures. The improved model re-enters the loop and the cycle compounds. Output: a better agent, ready for the next simulation run.What you get out of the loop
| Output | What it means |
|---|---|
| Reliability scores | Quantified agent performance across tasks and workflows |
| Operational insights | Failure modes, bottlenecks, and risks surfaced automatically |
| Training datasets | High-quality trajectories ready for RL / SFT / DPO |
| Deployment confidence | Ship agents you’ve validated against real task complexity |
Why BenchGen is different
- Operational, not synthetic — real systems, real workflows, real outcomes. Not toy benchmarks.
- Trajectory-first — BenchGen captures the full decision story, not just the final answer.
- Evaluation becomes learning — every run improves your agent and compounds your advantage.
- Private and sovereign — runs on your infrastructure. Your data never leaves.
Next steps
- Quickstart — run your first agent loop
- Agents overview — set up your simulation environment
- Eval overview — benchmark your agents
- Train overview — fine-tune on generated trajectories