A BenchGen environment bundle is aDocumentation Index
Fetch the complete documentation index at: https://docs.benchgen.com/llms.txt
Use this file to discover all available pages before exploring further.
.zip file. BenchGen unpacks it, reads the competition.yaml at the root, and assembles the environment from the files declared there.
Top-level layout
competition.yaml.
The two screenshots below show what a real code submission bundle (left) and dataset submission bundle (right) look like on disk:
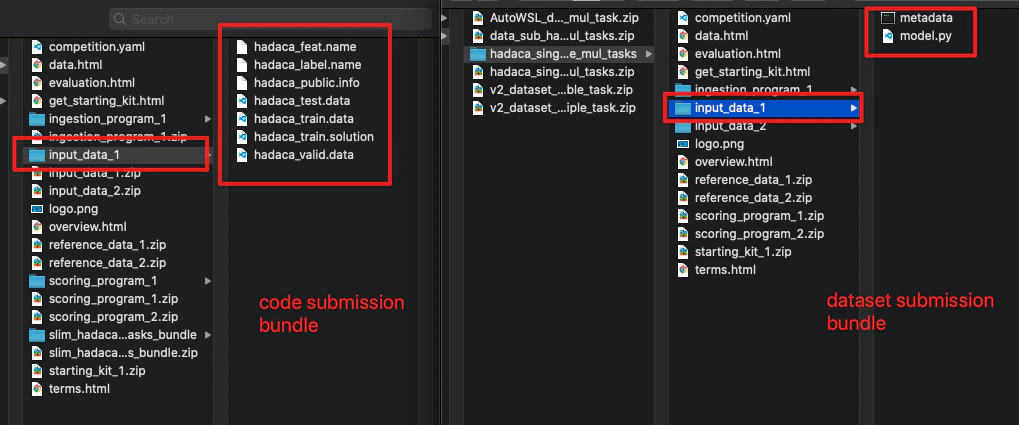
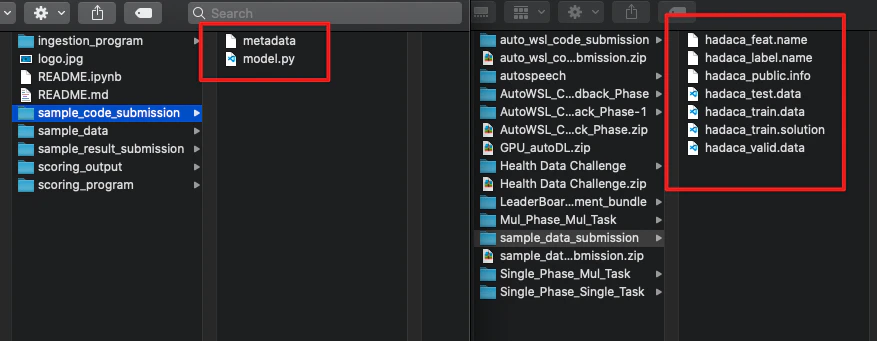
Files explained
competition.yaml
The only required file at the root. It defines the environment’s metadata, tasks, phases, and leaderboard. Every other file in the bundle is referenced from here.
See the YAML reference for a full field-by-field breakdown.
Reference data (reference_data.zip)
The ground-truth answers your scoring program uses to judge a model’s outputs. Only the scoring program reads this file — it is never exposed to the model being evaluated.
Reference data can be anything your scoring program can parse: CSV rows, JSON objects, plain text labels, or structured prediction targets. The format is entirely up to you as long as your scoring program can read it.
Scoring program (scoring_program.zip)
The script that decides whether a model’s output is correct. BenchGen runs this after every submission.
The zip must contain:
- Your scoring script (e.g.
scoring.py) - A
metadata.yamlthat specifies the command used to run it
metadata.yaml example:
| Path | Contents |
|---|---|
/app/input/res/ | The model’s predictions |
/app/input/ref/ | Your reference data |
/app/output/ | Where your script writes its results |
/app/program/ | Your scoring program files |
scores.json to /app/output/:
competition.yaml. Any additional keys are ignored.
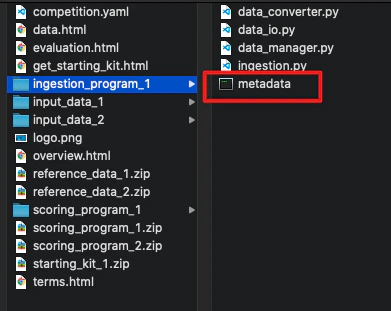
Ingestion program (ingestion_program.zip) — optional
An ingestion program is needed when BenchGen runs the model end-to-end as part of the evaluation rather than receiving pre-generated outputs. It takes input data, calls the model, and writes predictions that the scoring program then evaluates.
The zip must contain your ingestion script and a metadata.yaml file at the root of the folder:

metadata.yaml.
metadata.yaml example:
| Path | Contents |
|---|---|
/app/input_data/ | Your input data |
/app/ingested_program/ | The model submission being evaluated |
/app/output/ | Where predictions are written (read by scoring program) |
/app/program/ | Your ingestion program files |
metadata.yaml differs depending on your submission mode. In code submission mode the model code is $submission_program; in dataset submission mode the dataset is $submission_program and your sample code becomes $input:
Input data (input_data.zip) — optional
The test inputs handed to the ingestion program at run time. This is typically the prompt set, test features, or context documents your model needs to generate predictions. It is separate from the reference data so that the evaluation remains blind — the model sees inputs but never the answers.
Validation
When you upload a bundle, BenchGen checks:competition.yamlis present at the root and parses without errors- All files referenced in
competition.yamlexist inside the zip - The scoring program zip contains a
metadata.yamlwith acommandkey - Leaderboard column keys in
competition.yamlmatch at least one key expected inscores.json
Next steps
- YAML reference — all fields in
competition.yaml - Create a custom environment — end-to-end upload walkthrough